PortBLAS: Open Source BLAS that is Performance-Portable Across GPUs
I’ve been focusing on AI inferencing hardware over the past few months. In an earlier post, I have described the optimal hardware design for LLM inference. In a recent post, I have touched upon how PyTorch is an interpreter over CUDA code. In fact, it’s an interpreter over not just any cuda code but specific libraries from Nvidia like cuBLAS and cuDNN. In this post, we will build and benchmark a vendor neutral opensource implementation of BLAS called PortBLAS.
Background
Each GPU vendor supplies their own hand-tuned libraries for numerical routines such as cuBLAS, rocBLAS, or OneMKL. These libraries, likely hand-tuned to specific hardware using assembly, are not open source. The most important of all these procedures is unassuming matrix multiplication. BLAS, short for Basic Linear Algebra Subprograms, is the library interface which usually contains routines for matrix multiplications. In BLAS lingo, matrix multiplication is called gemm or short for General matrix multiply. For the rest of this post, we’ll use the term gemm to refer to matrix multiplication.
Matrix Multiplication Illustrated. Source: Wikipedia.
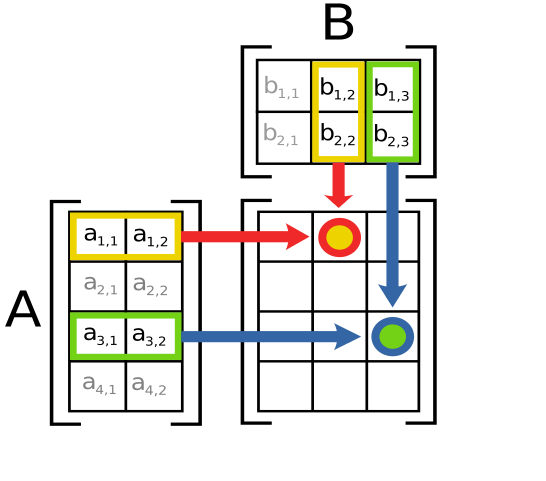
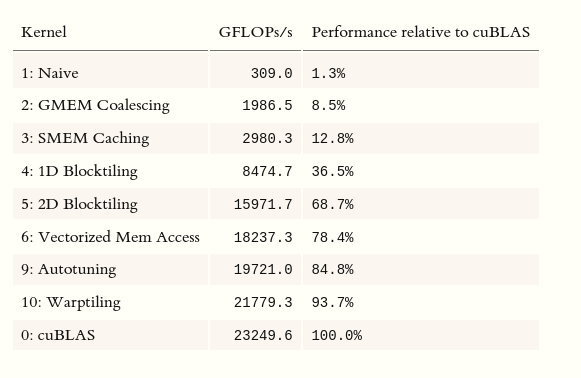
While gemm looks simple enough and obviously parallelizable on a GPU, it is one of the hardest things to write in a performant manner. The reason for this is deep and it is a topic for another post. In this post by Simon Boehm, kernels from naive to highly hardware tuned are written in CUDA and performance is compared with cuBLAS. You will be surprised to know that naively written code performs at 1% of what is achieved by cuBLAS. You can see that kernels that reach the performance use a lot of hardware specific features. This has two consequences:
- Writing kernels that are performant across GPU vendors is really hard
- If you use vendor libraries, you are locked into that vendor
Performance of GEMM kernels relative to cuBLAS. Source: Simon Boehm
The reason the vendor libraries are not open source might be more pedestrian than it seems. Very likely, these kernels are written in assembly by in-house experts on the architectures and they are not in a state where they can open source the code. If you’re a CPU programmer, you expect a compiler to optimize the code to best utilize the hardware features while you focus on algorithms and business logic. Unfortunately, the compilers in GPU world has not progressed where they can take three simple loops and optimize it to the best possible on a hardware.
You should now get why an open source BLAS that is fairly well performant across different vendors’ GPUs is exciting. There of course is an business angle that we can choose the best hardware for our problem without a vendor lock-in. It is also exciting technically because we can finally understand the optimizations that make GPU kernels highly performant. Imagine my excitement when I found a library from CodePlay software called PortBLAS which fits the bill! So, let’s get to work building and benchmarking it across GPUs!
Driver Sped Run
I’ll benchmark three GPUs I have access to:
As usual, I’ll use distrobox to create environments separate from the system environment. We will do speed run of installing drivers and stuff in them.
On Nvidia devices, you will have to install nvidia-container-toolkit and other stuff in the host system because Nvidia drivers are not part of Linux kernel. I will not go into details of this besides the following command. For other GPUs, you don’t need to install anything in the host system. In Intel and AMD GPUs though, we have to install drivers because we used containers.
# For Nvidia GPUs
distrobox create --name blas-reactor --additional-flags "--runtime=nvidia -e NVIDIA_VISIBLE_DEVICES=all -e NVIDIA_DRIVER_CAPABILITIES=all" --image nvidia/cuda:12.3.1-devel-ubuntu22.04
# For intel and AMD GPUs
distrobox create --name blas-reactor --image ubuntu:22.04
Then enter the distro using:
distrobox enter blas-reactor
Here are instructions for AMD GPUs:
# For AMD GPUs
wget http://repo.radeon.com/amdgpu-install/5.4/ubuntu/jammy/amdgpu-install_5.4.50400-1_all.deb
sudo apt install ./amdgpu-install_5.4.50400-1_all.deb
sudo apt update
sudo amdgpu-install --usecase=hip --no-dkms
And Instructions for Intel GPUs:
# For Intel GPUs
wget -qO - https://repositories.intel.com/gpu/intel-graphics.key | \
sudo gpg --dearmor --output /usr/share/keyrings/intel-graphics.gpg
echo "deb [arch=amd64,i386 signed-by=/usr/share/keyrings/intel-graphics.gpg] https://repositories.intel.com/gpu/ubuntu jammy client" | \
sudo tee /etc/apt/sources.list.d/intel-gpu-jammy.list
sudo apt update
sudo apt install -y \
intel-opencl-icd intel-level-zero-gpu level-zero \
intel-media-va-driver-non-free libmfx1 libmfxgen1 libvpl2 \
libegl-mesa0 libegl1-mesa libegl1-mesa-dev libgbm1 libgl1-mesa-dev libgl1-mesa-dri \
libglapi-mesa libgles2-mesa-dev libglx-mesa0 libigdgmm12 libxatracker2 mesa-va-drivers \
mesa-vdpau-drivers mesa-vulkan-drivers va-driver-all vainfo hwinfo clinfo xpu-smi
wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \ | gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" | sudo tee /etc/apt/sources.list.d/oneAPI.list
sudo apt update
sudo apt install -y intel-basekit
Once installed, restart the container
exit
distrobox stop blas-reactor
distrobox enter blas-reactor
Let’s verify if drivers work fine by doing smi commands:
# On Nvidia GPUs
$ nvidia-smi
Thu Feb 22 14:39:55 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 545.23.08 Driver Version: 545.23.08 CUDA Version: 12.3 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1650 Ti Off | 00000000:01:00.0 Off | N/A |
| N/A 54C P8 4W / 55W | 14MiB / 4096MiB | 0% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 1066 G /usr/lib/xorg/Xorg 9MiB |
| 0 N/A N/A 1225 G /usr/bin/gnome-shell 2MiB |
+---------------------------------------------------------------------------------------+
# On AMD GPUs
$ rocminfo | head
ROCk module is loaded
=====================
HSA System Attributes
=====================
Runtime Version: 1.1
System Timestamp Freq.: 1000.000000MHz
Sig. Max Wait Duration: 18446744073709551615 (0xFFFFFFFFFFFFFFFF) (timestamp count)
Machine Model: LARGE
System Endianness: LITTLE
# On Intel GPUs
$ xpu-smi discovery
+-----------+--------------------------------------------------------------------------------------+
| Device ID | Device Information |
+-----------+--------------------------------------------------------------------------------------+
| 0 | Device Name: Intel(R) Arc(TM) A770 Graphics |
| | Vendor Name: Intel(R) Corporation |
| | SOC UUID: 00000000-0000-0003-0000-000856a08086 |
| | PCI BDF Address: 0000:03:00.0 |
| | DRM Device: /dev/dri/card0 |
| | Function Type: physical |
+-----------+--------------------------------------------------------------------------------------+
Set up environments by doing the following:
# On Nvidia GPUs
export PATH=/usr/local/cuda/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}
# On AMD GPUs
export PATH=$PATH:/opt/rocm/bin:/opt/rocm/rocprofiler/bin:/opt/rocm/opencl/bin
export LD_LIBRARY_PATH=/opt/rocm/lib:/opt/rocm/lib64
export HSA_OVERRIDE_GFX_VERSION=10.3.0 # only for Van GOGH GPU
Benchmarking PortBLAS
That was kinda boring: let’s get into building portBLAS! PortBLAS is written in SYCL standard C++ which is an open source and open standards alternative to CUDA. Here’s the crazy part: we will use Intel’s implementation of this and it can emit code for all the three vendor devices! Install Intel OneAPI toolkit which includes this compiler.
# Only for Nvidia and AMD GPUs. We already installed for Intel GPUs above
wget -O- https://apt.repos.intel.com/intel-gpg-keys/GPG-PUB-KEY-INTEL-SW-PRODUCTS.PUB \ | gpg --dearmor | sudo tee /usr/share/keyrings/oneapi-archive-keyring.gpg > /dev/null
echo "deb [signed-by=/usr/share/keyrings/oneapi-archive-keyring.gpg] https://apt.repos.intel.com/oneapi all main" | sudo tee /etc/apt/sources.list.d/oneAPI.list
sudo apt update
sudo apt install -y intel-basekit git cmake ninja-build libopenblas-dev build-essential
We need to then install codeplay sycl runtime plugins for OneAPI for AMD and Nvidia GPUs. Unfortunately I don’t understand how this works beyond the fact they make these GPUs show up in sycl-ls. You need to go to browser, download the shell script manually and transfer them to the file. Follow these links for
- Nvidia GPUs: https://developer.codeplay.com/products/oneapi/nvidia/download
- AMD GPUs: https://developer.codeplay.com/products/oneapi/amd/download
OneAPI Plugin for Nvidia GPUs
# After download on Nvidia GPUs
sudo bash oneapi-for-nvidia-gpus-2024.0.0-cuda-12.0-linux.sh
# After download on AMD GPUs
sudo bash oneapi-for-amd-gpus-2024.0.0-rocm-5.4.3-linux.sh
# On both the CPUs
source /opt/intel/oneapi/setvars.sh
sycl-ls
sycl-ls should output something like this:
[opencl:acc:0] Intel(R) FPGA Emulation Platform for OpenCL(TM), Intel(R) FPGA Emulation Device OpenCL 1.2 [2023.16.12.0.12_195853.xmain-hotfix]
[opencl:cpu:1] Intel(R) OpenCL, AMD Custom APU 0405 OpenCL 3.0 (Build 0) [2023.16.12.0.12_195853.xmain-hotfix]
[ext_oneapi_hip:gpu:0] AMD HIP BACKEND, gfx1030 gfx1030 [HIP 50422.80]
This mean sycl runtime can detect our AMD GPU device. Now let’s clone the portBLAS repo:
git clone --recursive https://github.com/codeplaysoftware/portBLAS.git
cd portBLAS
mkdir build
cd build
Then let’s build. Note the DPCPP_SYCL_ARCH option has to be filled with relevant architecture. I have shown the values for my GPUs.
# For all GPUs (!)
source /opt/intel/oneapi/setvars.sh
export CC=/opt/intel/oneapi/2024.0/bin/compiler/clang
export CXX=/opt/intel/oneapi/2024.0/bin/compiler/clang++
# For Nvidia GPUs
cmake -GNinja ../ -DSYCL_COMPILER=dpcpp -DDPCPP_SYCL_ARCH=sm_75 -DDPCPP_SYCL_TARGET=nvptx64-nvidia-cuda -DTUNING_TARGET=NVIDIA_GPU -DCMAKE_BUILD_TYPE=Release
# For AMD GPUs
cmake -GNinja ../ -DSYCL_COMPILER=dpcpp -DDPCPP_SYCL_ARCH=gfx1030 -DDPCPP_SYCL_TARGET=amdgcn-amd-amdhsa -DTUNING_TARGET=AMD_GPU -DCMAKE_BUILD_TYPE=Release
# For Intel GPUs
cmake -GNinja ../ -DSYCL_COMPILER=dpcpp -DDPCPP_SYCL_TARGET=spir64 -DTUNING_TARGET=INTEL_GPU -DCMAKE_BUILD_TYPE=Release
# For all GPUs
ninja
It will take a while to build. Especially on laptops and devices like steamdeck. Now is the time for us to benchmark. We will prepare the parameters to the benchmark (matrix sizes) and run the benchmark.
# For all GPUs
cat << EOF > params.csv
n,n,1024,1024,1024,1,0
n,n,2048,2048,2048,1,0
n,n,4096,4096,4096,1,0
EOF
./benchmark/portblas/bench_gemm --csv-param params.csv --benchmark_out=../results.json \
--benchmark_out_format=json --benchmark_format=console
That’s it, this should run matrix multiplication (gemm) on the GPU and print some statistics. I have written a quick python script to extract out the relevant information from the json file. I compare it with vendor libraries using yet another benchmark I have written here.
| GPU | Matrix Size | PortBlas GFLOP/s | Vendor Libraries GFLOP/s | PortBlas/Vendor |
|---|---|---|---|---|
| Nvidia GTX 1650M | 1024 | 1284 | 1483 | 87% |
| 2048 | 2299 | 2700 | 85% | |
| 4096 | 2475 | 1889 | 131% | |
| AMD Van Gogh | 1024 | 451 | 889 | 51% |
| 2048 | 911 | 689 | 132% | |
| 4096 | 989 | 1199 | 82% | |
| Intel Arc 770 | 1024 | 7210 | 5271 | 137% |
| 2048 | 8473 | 1511 | 561% | |
| 4096 | 8408 | 16425 | 51% |
As you can see from the benchmarks, portBLAS performs quite respectably! We’re not getting 1% of the performance like you would get from a naive kernel. This is amazing!
In this post, we explored the challenges of tuning matrix multiplication routines on GPUs. We then understood the significance of open source BLAS that is performance portable across GPU devices. Finally, we compiled PortBLAS and benchmarked it against vendor libraries for GPU from all three major vendors. In a future post, we will see how PortBLAS functions.